
Training and Testing
How good is our nearest neighbor classifier? To answer this we’ll need to find out how frequently our classifications are correct. If a patient has chronic kidney disease, how likely is our classifier to pick that up?
If the patient is in our training set, we can find out immediately. We already know what class the patient is in. So we can just compare our prediction and the patient’s true class.
But the point of the classifier is to make predictions for new patients not in our training set. We don’t know what class these patients are in but we can make a prediction based on our classifier. How to find out whether the prediction is correct?
One way is to wait for further medical tests on the patient and then check whether or not our prediction agrees with the test results. With that approach, by the time we can say how likely our prediction is to be accurate, it is no longer useful for helping the patient.
Instead, we will try our classifier on some patients whose true classes are known. Then, we will compute the proportion of the time our classifier was correct. This proportion will serve as an estimate of the proportion of all new patients whose class our classifier will accurately predict. This is called testing.
Overly Optimistic “Testing”
The training set offers a very tempting set of patients on whom to test out our classifier, because we know the class of each patient in the training set.
But let’s be careful … there will be pitfalls ahead if we take this path. An example will show us why.
Suppose we use a 1-nearest neighbor classifier to predict whether a patient has chronic kidney disease, based on glucose and white blood cell count.
ckd.scatter('White Blood Cell Count', 'Glucose', colors='Color')
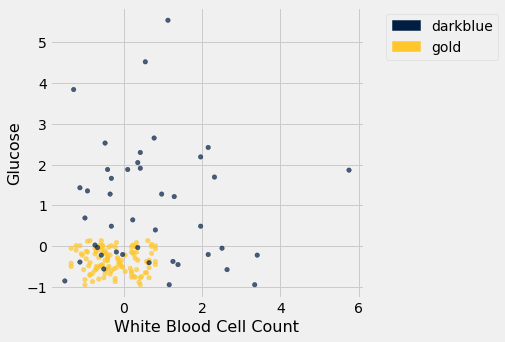
Earlier, we said that we expect to get some classifications wrong, because there’s some intermingling of blue and gold points in the lower-left.
But what about the points in the training set, that is, the points already on the scatter? Will we ever mis-classify them?
The answer is no. Remember that 1-nearest neighbor classification looks for the point in the training set that is nearest to the point being classified. Well, if the point being classified is already in the training set, then its nearest neighbor in the training set is itself! And therefore it will be classified as its own color, which will be correct because each point in the training set is already correctly colored.
In other words, if we use our training set to “test” our 1-nearest neighbor classifier, the classifier will pass the test 100% of the time.
Mission accomplished. What a great classifier!
No, not so much. A new point in the lower-left might easily be mis-classified, as we noted earlier. “100% accuracy” was a nice dream while it lasted.
The lesson of this example is not to use the training set to test a classifier that is based on it.
Generating a Test Set
In earlier chapters, we saw that random sampling could be used to estimate the proportion of individuals in a population that met some criterion. Unfortunately, we have just seen that the training set is not like a random sample from the population of all patients, in one important respect: Our classifier guesses correctly for a higher proportion of individuals in the training set than it does for individuals in the population.
When we computed confidence intervals for numerical parameters, we wanted to have many new random samples from a population, but we only had access to a single sample. We solved that problem by taking bootstrap resamples from our sample.
We will use an analogous idea to test our classifier. We will create two samples out of the original training set, use one of the samples as our training set, and the other one for testing.
So we will have three groups of individuals:
- a training set on which we can do any amount of exploration to build our classifier;
- a separate testing set on which to try out our classifier and see what fraction of times it classifies correctly;
- the underlying population of individuals for whom we don’t know the true classes; the hope is that our classifier will succeed about as well for these individuals as it did for our testing set.
How to generate the training and testing sets? You’ve guessed it – we’ll select at random.
There are 158 individuals in ckd. Let’s use a random half of them for training and the other half for testing. To do this, we’ll shuffle all the rows, take the first 79 as the training set, and the remaining 79 for testing.
shuffled_ckd = ckd.sample(with_replacement=False)
training = shuffled_ckd.take(np.arange(79))
testing = shuffled_ckd.take(np.arange(79, 158))
Now let’s construct our classifier based on the points in the training sample:
training.scatter('White Blood Cell Count', 'Glucose', colors='Color')
plt.xlim(-2, 6)
plt.ylim(-2, 6);
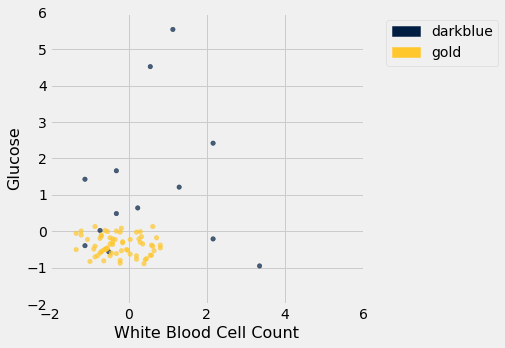
We get the following classification regions and decision boundary:
Place the test data on this graph and you can see at once that while the classifier got almost all the points right, there are some mistakes. For example, some blue points of the test set fall in the gold region of the classifier.
Some errors notwithstanding, it looks like the classifier does fairly well on the test set. Assuming that the original sample was drawn randomly from the underlying population, the hope is that the classifier will perform with similar accuracy on the overall population, since the test set was chosen randomly from the original sample.