
Empirical Distributions
In data science, the word “empirical” means “observed”. Empirical distributions are distributions of observed data, such as data in random samples.
In this section we will generate data and see what the empirical distribution looks like.
Our setting is a simple experiment: rolling a die multiple times and keeping track of which face appears. The table die contains the numbers of spots on the faces of a die. All the numbers appear exactly once, as we are assuming that the die is fair.
die = Table().with_column('Face', np.arange(1, 7, 1))
die
| Face |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
A Probability Distribution
The histogram below helps us visualize the fact that every face appears with probability 1/6. We say that the histogram shows the distribution of probabilities over all the possible faces. Since all the bars represent the same percent chance, the distribution is called uniform on the integers 1 through 6.
die_bins = np.arange(0.5, 6.6, 1)
die.hist(bins = die_bins)
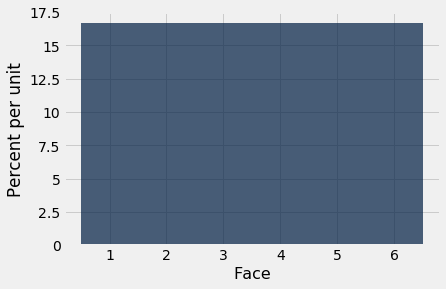
Variables whose successive values are separated by the same fixed amount, such as the values on rolls of a die (successive values separated by 1), fall into a class of variables that are called discrete. The histogram above is called a discrete histogram. Its bins are specified by the array die_bins and ensure that each bar is centered over the corresponding integer value.
It is important to remember that the die can’t show 1.3 spots, or 5.2 spots – it always shows an integer number of spots. But our visualization spreads the probability of each value over the area of a bar. While this might seem a bit arbitrary at this stage of the course, it will become important later when we overlay smooth curves over discrete histograms.
Before going further, let’s make sure that the numbers on the axes make sense. The probability of each face is 1/6, which is 16.67% when rounded to two decimal places. The width of each bin is 1 unit. So the height of each bar is 16.67% per unit. This agrees with the horizontal and vertical scales of the graph.
Empirical Distributions
The distribution above consists of the theoretical probability of each face. It is not based on data. It can be studied and understood without any dice being rolled.
Empirical distributions, on the other hand, are distributions of observed data. They can be visualized by empirical histograms.
Let us get some data by simulating rolls of a die. This can be done by sampling at random with replacement from the integers 1 through 6. We have used np.random.choice for such simulations before. But now we will introduce a Table method for doing this. This will make it possible for us to use our familiar Table methods for visualization.
TThe Table method is called sample. It draws at random with replacement from the rows of a table. Its argument is the sample size, and it returns a table consisting of the rows that were selected. An optional argument with_replacement=False specifies that the sample should be drawn without replacement, but that does not apply to rolling a die.
Here are the results of 10 rolls of a die.
die.sample(10)
| Face |
|---|
| 6 |
| 3 |
| 5 |
| 3 |
| 4 |
| 3 |
| 5 |
| 6 |
| 5 |
| 4 |
We can use the same method to simulate as many rolls as we like, and then draw empirical histograms of the results. Because we are going to do this repeatedly, we define a function empirical_hist_die that takes as its argument the sample size; the function rolls the die as many times as its argument and then draws a histogram.
def empirical_hist_die(n):
die.sample(n).hist(bins = die_bins)
Empirical Histograms
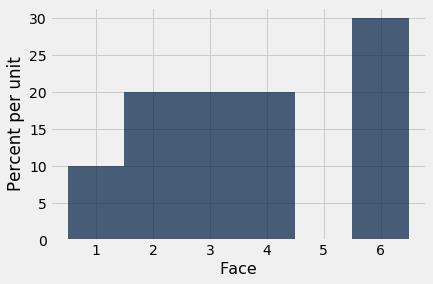
Here is an empirical histogram of 10 rolls. It doesn’t look very much like the probability histogram above. Run the cell a few times to see how it varies.
empirical_hist_die(10)
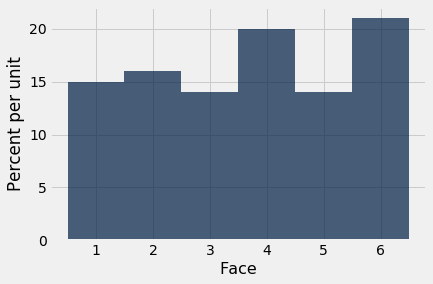
When the sample size increases, the empirical histogram begins to look more like the histogram of theoretical probabilities.
empirical_hist_die(100)
empirical_hist_die(1000)
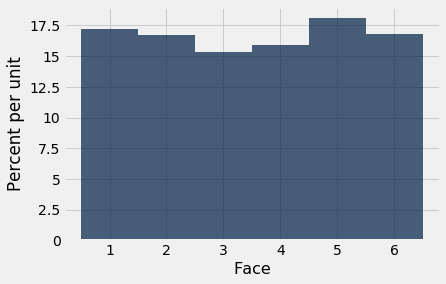
As we increase the number of rolls in the simulation, the area of each bar gets closer 16.67%, which is the area of each bar in the probability histogram.
What we have observed in an instance of a general rule:
The Law of Averages
If a chance experiment is repeated independently and under identical conditions, then, in the long run, the proportion of times that an event occurs gets closer and closer to the theoretical probability of the event.
For example, in the long run, the proportion of times the face with four spots appears gets closer and closer to 1/6.
Here “independently and under identical conditions” means that every repetition is performed in the same way regardless of the results of all the other repetitions.